譯者前言
對於 Rust 初學、尤其是之前慣用記憶體回收器語言(例如 Go、Python、Java)的開發者來說,Rust 提出的各種智慧指標種類繁多,各有其使用情境與限制,光是最單純的借用機制就常在生命週期限制下卡成一團,初學時面臨的各種編譯錯誤不免令人萌生退意。本文作者試圖從底層運作原理上解釋,並提出一些使用指標與架構上的原則;就算偷懶硬背其結論而不去深入理解,仍能維持一定的開發流暢性。
本文不免用到部份 C/C++ 用語,雖非理解本文所必要,仍鼓勵非 C/C++ 背景的開發者們在讀後試著瞭解一下那些概念。許多譯文用語儘量貼近本國用語,然而部份用字可能保留原文,以利讀者自行找尋第一手原文參考資料:
- 計算機科學中的 stack 和 heap 與其相關操作方法 pop & push
- Rust 語法定義的關鍵名詞,例如 trait
作者前言
本文主要是寫給正在入門 Rust、已理解基本的語法、卻正與編譯器纏鬥的開發者。我們將從底層的機器運作模型為出發點進行討論,如此更有助於讓人脫離對執行期垃圾回收機制的倚賴。我相信這樣的解釋方式比毫無頭緒地逐條解釋編譯資訊更有效率。
Rust 的記憶體管理機制相當巧妙,語意表現上很容易讓人忽略自己正在做什麼。這種設計導致編譯器錯誤報告相當不直覺。如果你對於計算機組織有基本的認識,知道函式的執行與記憶體互動原理,或是樂於學習這方面的知識,這篇文章將有效助你理解並流暢地使用 Rust。
一些心理準備
如果你想縱觀 Rust 全貌,你一定得把以下幾個要點牢記在腦海中:
- 從組合語言層級理解函式呼叫的運作原理。至少請記得什麼是 call stack、指標與 stack 之間的關係、以及 stack 在記憶體中的運作方式。如果你需要復習一下,YouTube 上可以找到一些關於計算機組織的教學影片。
- Heap 是一堆片段的記憶體區塊,而 stack 是有序、線性、且總是只從一端變化的記憶體空間。Heap 上可能產生不連續的遺棄資料。
- 多執行緒的情境,縱使每個執行緒各有各的 stack,但仍共用同一個 heap。
- 程式指令與靜態資料在程式開始時便一直存在,且不會被移動,因此我們總是能引用這些靜態資料。
妥善管理 Stack 上的資料
「擁有權」這種抽象概念體現於許多行為上,例如記憶體空間管理和指標操作。編譯器檢驗擁有權的同時,也保證我們永遠不會創造出無效的指標、或忘記回收記憶體空間。記憶體空間管理與擁有權之間的關係很直覺,如果我們不使用指標,RAII 資源回收機制會幫我們善後;編譯器鮮少在這種使用情境抱怨什麼。
然而,有時為了實作某些精巧的演算法,或為了避免在呼叫函式時一再複製資料,而希望在程式多處存取同一記憶體位址。我們確實需要指標。每當指標指涉的位址未隨著資料移動或銷毀,無效指標因而誕生。在 Rust 中,除了移動語意以外所有的擁有權合法性則規設計都為防止在 stack 中指涉無效資料。
接下來的內容,首先,我們會先來看看所有權與借用概念如何用在 stack 的運作上。接著,釐清所有在 heap 上放的資料資料所屬的 stack,我們得以將這些資料的生命週期與所有權反映在 stack 上。這些映射關係使我們得以清楚地確定資料銷毀的時間點,同時確保不會持有無效指標。
從正確的 Stack Pop 順序開始
注意:包括 x86 在內的架構設計上,stack 是從高位址往低位址成長,與電腦科學討論用的慣例有微妙的不同;因此在本文中,我們使用「上游(upstream)」與「下游(downstream)」這兩個字眼:呼叫函式進入「下游」,而後向「上游」傳回結果,回到本來發動呼叫的地方。
借用都是往下游遞送,以指向上游的資料。&T 總是指向上游 stack 內的資料 T,並總是比其指涉本體還要早被 pop 出去。
- 最單純常見的情境,
&T出現於下游,且指向上游的T - 將擁有權整合進資料結構時也適用上述情境。當
&T指向一個結構內的成員T,其後又將&T塞進其它結構體,則任何擁有&T的東西應往下游傳遞,並指回上游的T。 - 如此這般,
T總是在所有的&T都消失之後才被 pop 出 stack。 - 複雜結構的使用情境常常很難讓編譯器相信上述原則沒有被打破,單純情境則總是易於操作
在 pop 間保證因果關係
編譯器不容許在產生資料之後向其上游傳遞借用。這條規則有很多誤觸方式,包括試圖傳回一個區域資料的借用、在原資料生命週期不夠長的情況下把其借用塞進另一個資料結構、或是在現有出借行為未結束前試圖移動原資料。
以下是參數與傳回值傳遞時對於不同種資料擁有權的規則:
&T(借用)可以向下作為函式傳入參數,其內容指涉上層資料。T(擁有)可向下作為函式傳入參數。它可作為傳回值再度移回上層,或是隨著 stack 一同被回收。- 在所在函式內產生的資料
T可以被移往上層(離開當前 stack)或與該層 stack 共存亡。 - 若
&T指涉的對象是所在函式內擁有的資料,則此借用不可作為傳回值送進上層。只有資料所有權本身可以往上傳回,因為該資料本身會隨著函式結束而消失,進而使得&T指向不合法的位址。 - 如果該
&T本已作為參數被傳入,那麼同樣也能傳回上層。
資料間的相對關係會在函式呼叫間保留,這些關係因此可在不同 stack 之間跨層傳遞。一般而言,資料都會往上游(過去)指涉,而向下游(未來)傳送或夾帶。你也可以把這些規則歸納成兩條:
- 傳入借用或所有權
- 傳回所有權,或是指向仍存在的上游資料的借用
好,現在你開始有個底。我們現在知道 stack 上資料的正確清除順序,也為此訂下一些規則以確保不會發生意外。現在讓我們來看看 heap。
利用 Box 把擁有權放在 Heap 上
Box<T> 是一種擁有權指標,其內部有一個指標,指向一塊放在 heap 上的資料。Box<T> 是一個放在 stack 上的 Box 與放在 heap 上的 T 的合成物。它實際上就是在 heap 上的一塊你擁有的資料。你可以傳遞它、移動它、改變它所指涉的目標,也可以將之作為傳回值。當它被銷毀時,它所對應在 heap 上的空間、資料內擁有的其它資料也會同時被回收。Box 的借用(&Box)同前節所述可以被向下傳遞、而只能在不超過 Box 壽命範圍內向上傳遞。
你可以籍由呼叫 Box::new(myT) 以把 T 移上 heap。在呼叫之前,資料都還位於 stack 上,而在呼叫後搬上 heap。Arc::new(myT) 是另一種把資料搬上 heap 的容器,一樣是在產生容器的過程把資料搬上去。Vec::with_capacity(usize) 是一種可變大小的 heap 空間,你隨時可以籍由 push 把資料放上去;Vec 的所有權在你手上,而其內資料被 Vec 擁有。
- Stack 擁有 heap
- 當 stack 失去其所擁有的 heap → heap 上的資料隨之銷毀
受到 Box 掌握的 heap 會一直存活到 Box 壽命結束。一般而言,heap 上的空間當視為 stack 的衍伸空間,而 stack 本身的生命週期相當簡單直覺。
即便你弄出像是 Box<…Box<Box<T>>…> 的東西,把一堆指標一起扔上 heap,這些東西依然受到最外層的容器 Box 所掌握,最外層容器仍位於 stack 上,結繫在函式的能見範圍裡,終將隨著函式的結束而一個一個跟著被回收。另一方面,就算籍由 Box::new(&myT) 把借用扔上 heap,你仍無法只留下資料所有權的同時把這個包裝用的 Box 當作傳回值。把借用放上 heap 並不會把讓 &T 憑空變出可傳遞性。
這些抽象概念讓我們幾乎不需要手動處理記憶體區塊的配置與釋放。你仍可以利用 std::mem 來配置記憶體,但這並非常見手法。
引用計數的生命週期
我們必須來特別探討一下 Rc 和 Arc(Atomic reference counter,原子化引用計數)在 heap 與 stack 的使用情境。我們無法確定某些資料需要存在多久,因此將之放上 heap 並以引用計數來管理。Arc 是原子化計數,因此可跨執行緒使用;Rc 則是一般性把資料放上 heap 的版本。這些引用計數容器像是放在 stack 上的遙控器,可以任意傳遞傳回,而且可以多次複製,只有在最後一個備份被銷毀時才會動手清除其內指涉的資料。這種容器本身並不提供其內資料的可變性,但你可以把可變資料包裝後塞在裡面。
借用的生命週期 = 不可移動的區間
當資料已出借的期間內,其本體便不可被移動。當一個借用指向被移動過的資料,實際上就是一個懸置指標。Rc 和 Arc 便是可行的替代方案,可以任意地被複製(copy / clone)其所指涉內容,或是傳遞引用計數本身。另一個選項則是一開始就把所有權設計在上游,如此一來下游都只是在移動借用。
將多個所有權結合在一起,就會產生生命週期註記
每當你創造東西,它就會有生命週期;但如果它引用指涉了另一個不同生命週期的東西,你就開始需要生命週期註記(lifetime annotation)。這些註記與所有權息息相關。編譯器會檢查這些註記與所有權關係是否與實際所需生命週期一致。
最直接的例子,你試著設計一種資料結構,而這種結構有個成員借用了另一些資料,編譯器會馬上開始問生命週期相關細節。如果你有兩個引用,編譯器會試圖釐清這兩個引用對象的生命週期究竟是否相同。生命週期註記的存在就是為了計算這些資訊。
函式呼叫需要事先確定所需空間
當編譯器發出 unsized types 警告時,是在告訴我們它需要這些容量資訊來規劃 stack 上的記憶體分配方式。編譯器可以處理任意數量的函式呼叫或記憶體對齊等細節,但若無法確定資料型態所佔容量,則編譯器將不知如何將它塞進 stack。
- 需要把未知容量資料作為傳入參數?請用
&或Box或其它已知容量的容器包裝它 - 需要把未知容量資料作為傳回值?我們無法將區域變數的引用(
&)傳出它的存在範圍,請改用Box包裝它 - 借用(&)只是一種指標,而指標的大小是固定的:
fn (foo: & dyn Trait) { .. } - 陣列大小要在執行期才能決定?或是大小有變動的可能性?你需要 heap,意即需要一個
Box - 數值實際型別可能有好幾種?或是需要把不同型別的東西放在同一個容器內?
Vec<Box<dyn Trait>>可以幫你盛裝各種不同但皆實作某一Trait的資料,而foo (t: & dyn Trait)這樣的函式允許傳入各種已實作特定Trait的資料 - 記住:像是
Vec::push等等各種容器操作都須先決定傳入值的容量資訊
編譯器可能為了各種不能確定資料大小的狀況而抱怨。Box 本身的大小是確定的,且是一種資料擁有者。每當無法在編譯期確定資料大小時,請善用 Box 把那些資料放上 heap。
Struct 也需要佔用空間
函式的傳入與傳回值都是由你設計的,你可以推算得出容量資訊。對於那些特殊容量的資料型態(譯註:例如 &[T; length]),其容量標註在最後的欄位裡面。
引入物件導向設計
從前在寫有垃圾回收機制的語言,你可以把一堆相關的資料與處理邏輯通通塞進一個 class,隔絕內外部狀態變換邏輯,並享受分割 API 帶來的好處。然而在 Rust 的世界裡,所有權借用的概念迫使我們必須連帶考量資料大小與存在時間相關要素。C 和 C++ 的開發者們過去利用指標來處理這類事務。
我可以定義
struct。這些struct各有其對應的成員方法,讓我處理各式&self、self和Self,且在此還有些叫作 trait object 的玩意。雖說沒有繼承機制,但我可以用這些語言特性實作物件導向設計嗎?
可以,但也不能完全自由發揮。千萬不要在可解藕生命週期的情況下把不相關的資料包裝在一起。如果一個借用目標的生命週期與你的 struct 不同,你便不得不開始面對那些炫炮難搞的生命週期註記。請儘量從那些較為迷你單純的 struct 開始設計,並把其對應的成員方法介面單純化,以利未來使用在不同的地方。
千萬不要從建構式裡面借用資料
DontBorrowFromConstructorScopeValues::new()
建構式也只是一種函式。在不得不撰寫複雜的建構式時,記住 T 和 &T 的傳遞原則。千萬別從區域變數產生資料之後又將它的借用塞進另一個 struct。你的資料結構必須直接擁有那些資料,或是借用自上游。
一般來說,你可以不要在建構式裡面借用自身成員;千萬別這樣搞自己,你將無法輕易移動這種資料結構的擁有權,除非用上某些奇技淫巧。如果資料成員以這種方式借用,其生命週期會對不起來。你只能把結構性資料向下游借出,進入結構內部,傳回已借用的部份資料借用,或是再向下游傳遞借用。
我真的需要多態(polymorphism)嗎?
如果你需要在一段程式裡面輪替使用一些不同型別實作的同一種方法,且這種方法屬於特定的 trait(trait 可以說是在 Rust 裡面最接近 interface 語意的介面宣告),則這是使用 trait object 的好機會。當你利用 dyn 關鍵字將變數綁定特定的 trait 而非型別,trait object 隨之產生。
fn polycaller(thing: Box<dyn Trait>) {
thing.trait_method()
}
以上這種函式呼叫便是一種多態的表現,實際上的行為是利用 vtable(virtual table, 虛擬函式表)在執行期決定其行為。舉例來說,Vec<Box<dyn Trait>> 可以用以儲存一連串實作同一 trait 的各種物件。Trait object 幫助我們統一並限制這些物件的行為。
一個常令入門者意外的點是,由於這種執行期的型別不確定性,因此必須籍由借用、或包裝後放上 heap 才能作為參數傳遞;畢竟編譯器在安排函式呼叫行為前必須先確定 stack 容量需求,像這種必須執期行動態查找 vtable 才能決定實際呼叫對象的運作機制是無法直接編譯的。
容器的選用幾乎可以視為語言層面的文法問題
你在使用變數時需要考量的點在於,資料應存在哪種空間裡、如何避免資料競爭、是否需要再次覆寫、需要多長的生命週期。變數借用只是一種文法表現,不產生額外成本,卻保留了執行期顯式或隱式函式呼叫的彈性。C 語言中等同於 Box 的寫法基本上就只是個指標,而 Rust 中 Box::new(myT) 語意上卻也包括了 malloc。這就是為何當初設計語言時僅將這些機制設計成容器型別,而不直接嵌進文法。
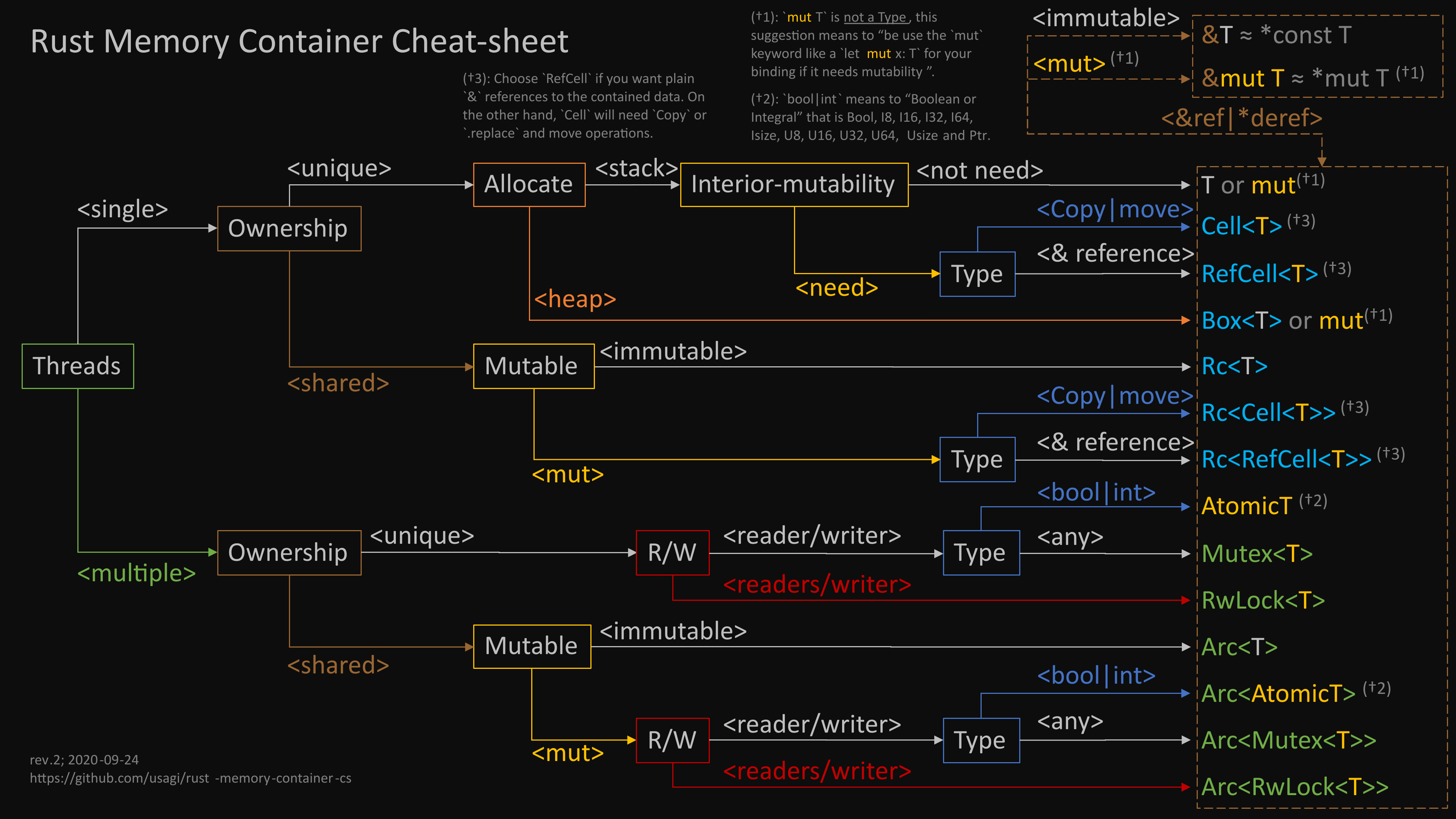
TL;DR 以下這幾種常見容器的使用時機:
Single Thread 單一執行緒
- 可能有多個所有權持有者、且資料放在 heap 上:
Rc<T> - 不可變引用、但未來可能需要所指涉對象的內容可變性:
Cell<T> - 需要對不可複製(copy)對象保有內部可變性、或是該對象內部亦有保有內部可變性需求:
&mut self RefCell<T>
Multi-Threaded 跨執行緒
- 可能有多個所有權持有者、且資料放在 heap 上:
Arc<T> - 不但多持有者、且讀寫行為具有排它性:
Arc<Mutex<T>> - 不但多持有者、寫入行為具排它性、但允許共時讀取:
Arc<RwLock<T>>
筆者認為除了《The Rust Programming Language》以外,這是將容器使用方法解釋得最好的一篇文章。
Rust 的世界中,多執行緒環境下的情境更為單純
由於可以移入、甚至在不同執行緒間傳遞的資料種類相當有限,你可以用在跨執行緒的邊界處理手段反而比前述 stack 與 heap 更為單純。此其中唯一的難點在於,如何將本來用在單一執行緒內部的資料組合,運用在多執行緒情境。
執行緒彼此不分享 stack
執行緒彼此無法預測其它執行緒上資料的生命週期,因此把指標指向其它執行緒 stack 內的資料是不安全的。想在這樣的情境下共享資料,勢必得讓資料以某種形式存在於 heap 上。
你用 clone 產生並操作那些放在 stack 裡的 Arc,實際資料與引用計數則理所當然位於 heap 裡。這樣的操作介面使得各執行緒得以各自處理資料生命週期。
而所有需要跨執行緒共用的指標,其所指目標也都必須放在 heap 上,不可在 stack 裡。
遞送並非共享
Sync是可用來跨執行緒分享的 traitSend則是用來跨執行緒移動的 trait
所謂的 send 行為,大致是先將資料擁有權移進一個緩衝區,而後交給另一個執行緒,從緩衝區再度移進該執行緒的 stack。遞送一個 Box 並非罕見行為。當使用一些第三方 crate 自定義的資料型別時,可用在跨執行緒的型別通常會宣告成 Send + Sync;但當 API 只想將這類特性用於內部實作時,也可以籍由隱藏 Send 或 Sync 以避免使用者誤用。
確保只有一個擁有者 + 可移動或可復製 ≈ 可以在執行緒間遞送
關鍵字:send。Box、struct、Cell 這種單一擁有者、可移動的資料,可以被包裝並透過像是 std::sync::mpsc::channel 之類的介面進行傳遞。
具有 Copy 性質的資料,通常是一些我們不在乎其是否為同一個體的資料(例如 777u32),也總是可以被傳遞。
正在被借用的資料不可被移動,當然也不可被傳遞。某些特定型別不允許移動,也因此無法被傳遞。
Rc 就是一種非固定擁有者的例子。你無法確定現在有多少使用者,無法將其轉換為單一擁有者的資料型別,因此無法將它傳遞到別的執行緒上。其內部的引用計數計算並不保證原子性,以致無法正確地跨執行緒追蹤資料生命週期。
執行緒間只能在資料擁有權與可變性的分享上保證原子性
就算只讀不寫,你仍必須保證資料在需要的時候依舊存在。為了避免造成未定義行為,你必須防止資料競爭;而如前文所述,你不能直接使用那些把生命週期結繫在另一個 stack 上的東西,結論就是你必須用 Arc 這種既可複製又可傳遞的包裝,來跨 stack 存取資料。
那些本身即具原子性的資料型別,籍由正確安全的資料存取設計,讓我們得以在擁有權與生命週期系統的管制下安全地使用它們,並進而預防資料競爭問題。
跨執行緒分享 ≈ 在 heap 上具有原子性的東西
每當你想在執行緒間分享某些資料,因為 Rust 不會放任你做出孕釀資料競爭的溫床,你遲早會發現最直覺的做法即是採用那些已設計用來保證原子性的型別,或是它們的衍伸型別,例如 Arc、AtomicBool、Mutex 等等。
最容易在 heap 上處理這類事務的就是 Arc。當你需要自動且正確地處理布林值時,Arc<AtomicBool> 是最佳選擇,或是用 Arc 包裝的其它原子性型別。AtomicBool 和那些定義在 std::sync::atomic 裡的型別們,在多執行緒情境下非常好用。
至此,我們只用了相當小的篇幅討論 Rust 底層視角下的跨執行緒資料分享。在這個情境中,所有的可用性與可變性都被限制包裝在原子性容器之中,而資料內容變動與生命週期的維護都發生在 heap 上。以執行緒安全為前題,最易變、最不可測的資料無疑會以最受限的 API 所管制。
進階閱讀
- Container cheat sheet with excellent memory layout diagrams
- Rust Book section on stack & heap in relation to ownership
- What are the Allocation Rules?
- Global Memory Usage: The Whole World
- Fixed Memory: Stacking Up
作者後記:為何從底層運作為出發點?
《The Rust book》試圖用一種語言設計理論的角度解釋資料生命週期,讓你從抽象後的行為開始學習,而非出於執行機制。該著作有提到一些 heap,但對於已理解底層運作的高階語言使用者而言,這樣的解釋方式確實易使人感到無所適從。在釐清底層機器運作與高階學術性質模型之間的關聯之前,語言學習者很容易受到編譯器的震憾教育。
類似於底層機器運作式的心智模型對於學習有莫大幫助;雖然純抽象理論式學習遲早能讓人上手,但個人認為這種作法的學習效率不佳。機器運作相關知識不難入門,且裨益良多,系統程式開發者遲早需要學習底層運作機制,因此簡化的執行模型對於程式開發者而言有不錯的解釋效果。
部份抱怨提到,這篇文章掩飾了許多編譯器理論上可以達成、在語言理論上合理卻違反直覺或難以簡單解釋的部份。直接解釋運作原理可以讓人快速吸收概念,且不含任何欺瞞成份。另一方面,如果擁有權與生命週期的抽象概念比機器運作更為基礎,我們便難以檢視其概念與抽象機模型之間概念轉換的完整性。直接從完全抽象概念作為出發點也許並不那麼理想。
C 和 C++ 背景的開發者們對於這類艱澀且大量的底層資訊可能習以為常;但對於 Java 和 .Net 業界人士、甚至 Python 或 JavaScript 使用者而言,無論變數允不允借用、哪些東西可否用於參數或回傳值、如何跨執行緒傳遞資料,這些細節在過去常被忽略,因此在討論這類議題時我們不得重新從底層運作從頭闡述。
我必須承認,在這篇文章中仍有許多關於執行緒的細節未討論,且忽略 Rust 中那些標註為 unsafe 的部份功能。如果對於初入此領域者沒有幫助,這部份就不會被納入本文討論範圍,這也是為何我將環狀引用問題與 Weak<T> 相關章節移除的原因。
譯者後記
本文旨在解釋生命週期運作概念、因應這些設計需求而生的資料型別的使用時機與禁忌。文中提到容器種類繁多,或許一時難以牢記,以下這張小抄或許有助快速複習:Rust Memory Container Cheat-sheet