數據操作(Pandas) 完整
1.1. pandas 對象
引入 pandas 等包,DataFrame、Series 屬於常用的,所以直接引入
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
DataFrame 對象:Pandas DataFrame 是一個表格型的數據結構,有行索引也有列索引
from IPython.display import Image
Image(filename='../../image/DataFrame.png', width=400)
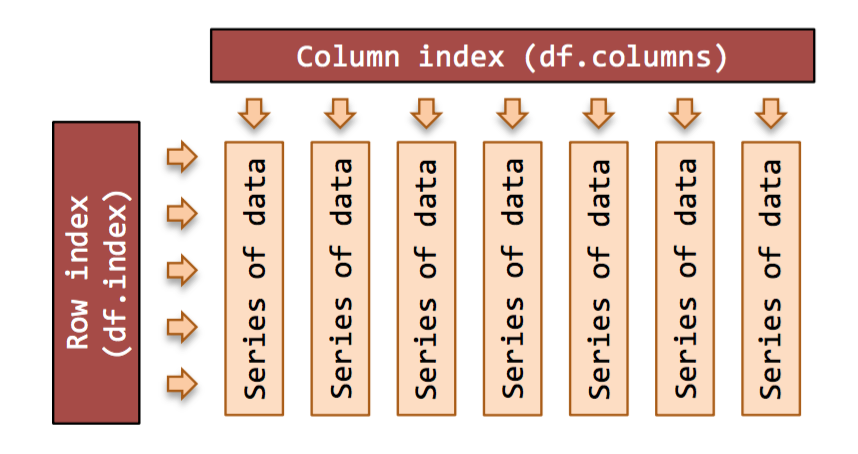
Series 對象:類似於一維數組的對象,由一組同樣 type 的數組和索引組成
s1 = Series(range(0,4)) # -> 0, 1, 2, 3
s2 = Series(range(1,5)) # -> 1, 2, 3, 4
s3 = s1 + s2 # -> 1, 3, 5, 7
s4 = Series(['a','b'])*3 # -> 'aaa','bbb'
index 對象:即 Series 和 DataFrame 的索引
# 獲取索引
df = DataFrame(s1)
idx = s1.index
idx = df.columns # the column index
idx = df.index # the row index
# 索引的一些特性
b = idx.is_monotonic_decreasing
b = idx.is_monotonic_increasing
b = idx.has_duplicates
i = idx.nlevels # multi-level indexe
# 索引的一些方法
a = idx.values # get as numpy array
l = idx.tolist() # get as a python list
# idx = idx.astype(dtype) # change data type
# b = idx.equals(other) # check for equality 看看是否是相同的索引
# union of two indexes 合併兩個索引
# idx = idx.union(other)
idx1 = pd.Index([1, 2, 3, 4])
idx2 = pd.Index([3, 4, 5, 6])
idx1.union(idx2)
Int64Index([1, 2, 3, 4, 5, 6], dtype='int64')
i = idx.nunique() # number unique labels
label = idx.min() # minimum label
label = idx.max() # maximum label
創建 Series 和 DataFrame
http://pandas.pydata.org/pandas-docs/stable/dsintro.html
1.2. DataFrame 入門
df = DataFrame(np.random.randn(10, 4), columns=['A', 'B', 'C', 'D'])
DataFrame 的一些實用查看方法
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 4 columns):
A 10 non-null float64
B 10 non-null float64
C 10 non-null float64
D 10 non-null float64
dtypes: float64(4)
memory usage: 392.0 bytes
n=4
dfh = df.head(n) # 看前 n 行
dft = df.tail(n) # 看後 n 行
dfs = df.describe() # 各類統計信息
top_left_corner_df = df.iloc[:5, :5]
dfT = df.T # transpose rows and cols
DataFrame index 的一些特性
l = df.axes # list row and col indexes
l
[RangeIndex(start=0, stop=10, step=1),
Index([u'A', u'B', u'C', u'D'], dtype='object')]
(r, c) = df.axes # from above
s = df.dtypes # Series column data types
A float64
B float64
C float64
D float64
dtype: object
b = df.empty # True for empty DataFrame
b
False
i = df.ndim # number of axes (2)
i
2
t = df.shape # (row-count, column-count)
t
(10, 4)
(r, c) = df.shape # from above
(r, c)
(10, 4)
i = df.size # row-count * column-count
i
40
a = df.values # get a numpy array for df
實用方法
df = DataFrame([1, 23, 3, 5, 2])
dfc = df.copy() # copy a DataFrame
dfr = df.rank() # rank each col (default) 把每個值的地位列出了
dfs = df.sort() # sort each col (default)
# dfc = df.astype(dtype) # type conversion
/Users/Scott/Library/anaconda2/lib/python2.7/site-packages/ipykernel/__main__.py:3: FutureWarning: sort(....) is deprecated, use sort_index(.....)
app.launch_new_instance()
# 下面的兩個方法沒怎麼搞懂
df.iteritems()# (col-index, Series) pairs
df.iterrows() # (row-index, Series) pairs
# example ... iterating over columns
for (name, series) in df.iteritems():
print('Col name: ' + str(name))
print('First value: ' +
str(series.iat[0]) + '\n')
Col name: 0
First value: 1
通用函數
| method | ## |
|---|---|
| df = df.abs() | absolute values |
| df = df.add(o) | add df, Series or value |
| s = df.count() | non NA/null values |
| df = df.cummax() | (cols default axis) |
| df = df.cummin() | (cols default axis) |
| df = df.cumsum() | (cols default axis) |
| df = df.cumprod() | (cols default axis) |
| df = df.diff() | 1st diff (col def axis) |
| df = df.div(o) | div by df, Series, value |
| df = df.dot(o) | matrix dot product |
| s = df.max() | max of axis (col def) |
| s = df.mean() | mean (col default axis) |
| s = df.median() | median (col default) |
| s = df.min() | min of axis (col def) |
| df = df.mul(o) | mul by df Series val |
| s = df.sum() | sum axis (cols default) |
1.3. DataFrame Columns 列處理
column 其實也是一個 Series
df = DataFrame(np.random.randn(10, 4), columns=['A', 'B', 'C', 'D'])
idx = df.columns # get col index
label = df.columns[0] # 1st col label
lst = df.columns.tolist() # get as a list
lst
['A', 'B', 'C', 'D']
In [32]:
label
Out[32]:
'A'
In [33]:
idx
Out[33]:
Index([u'A', u'B', u'C', u'D'], dtype='object')
column 改名
# df.rename(columns={'old':'new'}, inplace=True)
# df = df.rename(columns={'a':1,'b':'x'})
選擇 columns, 也就是提取列
s = df['C'] # select col to Series
df = df[['C']] # select col to df
df = df[['A','B']] # select 2 or more
df = df[['C', 'B', 'A']]# change order 改變排序了
s = df[df.columns[0]] # select by number
f = df[df.columns[[0, 3, 4]] # by number
s = df.pop('C') # get col & drop from df == df['C']
用 python 特性提取列
s = df.A # same as s = df['A'],
# 但不能用 python 特性創建新的 columns
# df['new_col'] = df.a / df.b
添加新的 columns,添加一個 column 是極為方便的,只要能添加一組數據就行
df['new_col'] = range(len(df))
df['new_col'] = np.repeat(np.nan,len(df))
df['random'] = np.random.rand(len(df))
df['index_as_col'] = df.index
df.head(2)
| A | B | C | D | new_col | random | index_as_col | |
|---|---|---|---|---|---|---|---|
| 0 | 0.458326 | -1.402187 | 0.446208 | -0.459079 | NaN | 0.920599 | 0 |
| 1 | 0.366833 | 0.618661 | -0.727332 | 1.152775 | NaN | 0.503750 | 1 |
詳情參考 df1[[‘b’,’c’]] = df2[[‘e’,’f’]] df3 = df1.append(other=df2)
判定函數 pd.Series.where
# 符合 >0 條件的保持原值,其他 =0
df['A'] = df['A'].where(df['A']>0, other=0)
# df['d']=df['a'].where(df.b!=0,other=df.c)
數據格式 轉換一列的格式時非常有用。
s = df[‘col’].astype(str) # Series dtype na = df[‘col’].values # numpy array pl = df[‘col’].tolist() # python list
columns 的一些特性和方法
value = df[‘col’].dtype # type of data value = df[‘col’].size # col dimensions value = df[‘col’].count()# non-NA count value = df[‘col’].sum() value = df[‘col’].prod() value = df[‘col’].min() value = df[‘col’].max() value = df[‘col’].mean() value = df[‘col’].median() value = df[‘col’].cov(df[‘col2’]) s = df[‘col’].describe() s = df[‘col’].value_counts()
找出最小值和最大值的位置
df['B'].idxmax()
df['B'].idxmin()
7
元素級方法
s = df[‘col’].isnull() s = df[‘col’].notnull() # not isnull() s = df[‘col’].astype(float) s = df[‘col’].round(decimals=0) s = df[‘col’].diff(periods=1) s = df[‘col’].shift(periods=1) s = df[‘col’].to_datetime() s = df[‘col’].fillna(0) # replace NaN w 0 s = df[‘col’].cumsum() s = df[‘col’].cumprod() s = df[‘col’].pct_change(periods=4) s = df[‘col’].rolling_sum(periods=4, window=4)
df = df.mul(s, axis=0) # on matched rows,相當於 * other Series 每行都與之相乘
df.columns.get_loc('B')
0
df = df.iloc[:, 0:2] # exclusive
獲取 columns 的具體位置
df
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohino | 1.5 | NaN |
| two | 2001 | Ohino | 1.7 | NaN |
| three | 2002 | Ohino | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
下面那個好像沒什麼軟用
In [167]:
for i in ['pop', 'state']:
print df.columns.get_loc(i)
2
1
In [152]:
Series(df.columns)
Out[152]:
0 year
1 state
2 pop
3 debt
dtype: object
1.4. DataFrame rows 行處理
獲取索引和標籤
idx = df.index # get row index
label = df.index[0] # 1st row label
lst = df.index.tolist() # get as a list
改變索引或行名
df.index = idx # new ad hoc index
df.index = range(len(df)) # set with list
df = df.reset_index() # replace old w new
# note: old index stored as a col in df
df = df.reindex(index=range(len(df)))
df = df.set_index(keys=['r1','r2','etc'])
df.rename(index={'old':'new'},inplace=True)
Drop row 刪除行
df = df.drop(‘row_label’) df = df.drop(row1) # multi-row df = df.drop([‘row1’,’row2’]) # multi-row
查找一些行
In [23]:
# fake up some data
data = {1:[1,2,3], 2:[4,1,9], 3:[1,8,27]}
df = pd.DataFrame(data)
In [4]:
# multi-column isin
lf = {1:[1, 3], 3:[8, 27]} # look for
f = df[df[list(lf)].isin(lf).all(axis=1)] # 這裡看不太懂
對行做排序
df_obj.sort(columns = ‘’)#按列名進行排序
df_obj.sort_index(by=[‘’,’’])#多列排序,使用時報該函數已過時,請用sort_values
df_obj.sort_values(by=['',''])同上
索引前奏
df0 = DataFrame({'x': [1, 2, 3], 'y': [3, 4, 5]}, index=[3, 2, 1])
df1 = DataFrame([[1, 2, 3,], [3, 4, 5], [6, 7, 8]], index=[3, 2, 1])
df0
| x | y | |
|---|---|---|
| 3 | 1 | 3 |
| 2 | 2 | 4 |
| 1 | 3 | 5 |
df0[1:2]
| x | y | |
|---|---|---|
| 2 | 2 | 4 |
df1
| 0 | 1 | 2 | |
|---|---|---|---|
| 3 | 1 | 2 | 3 |
| 2 | 3 | 4 | 5 |
| 1 | 6 | 7 | 8 |
df1[0]
3 1
2 3
1 6
Name: 0, dtype: int64
df1[0:2]
| 0 | 1 | 2 | |
|---|---|---|---|
| 3 | 1 | 2 | 3 |
| 2 | 3 | 4 | 5 |
df1.ix[:, 0:2]
| 0 | 1 | 2 | |
|---|---|---|---|
| 3 | 1 | 2 | 3 |
| 2 | 3 | 4 | 5 |
| 1 | 6 | 7 | 8 |
df0[['x','y']]
| x | y | |
|---|---|---|
| 3 | 1 | 3 |
| 2 | 2 | 4 |
| 1 | 3 | 5 |
1.5. 索引和切片
整數時一般是不包含的,非整數則會包含尾巴(基於 label)
foo = DataFrame([4.5, 7.2, -5.3, 3.6], index=['a', 'b', 'c', 'd'])
bar = DataFrame([4.5, 7.2, -5.3, 3.6], index=range(4))
print(foo)
print '------'
print(bar)
0
a 4.5
b 7.2
c -5.3
d 3.6
------
0
0 4.5
1 7.2
2 -5.3
3 3.6
print foo[:2]
print '------'
print bar[:2]
print '------'
print foo[:'c']
0
a 4.5
b 7.2
------
0
0 4.5
1 7.2
------
0
a 4.5
b 7.2
c -5.3
ix[::, ::] 可以接受兩套切片(axis=0)橫向,(axis=1)列向
data = {'state':['Ohino','Ohino','Ohino','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
df = DataFrame(data,index=['one','two','three','four','five'],
columns=['year','state','pop','debt'])
df
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohino | 1.5 | NaN |
| two | 2001 | Ohino | 1.7 | NaN |
| three | 2002 | Ohino | 3.6 | NaN |
| four | 2001 | Nevada | 2.4 | NaN |
| five | 2002 | Nevada | 2.9 | NaN |
df.ix[:, 'state':'pop']
| state | pop | |
|---|---|---|
| one | Ohino | 1.5 |
| two | Ohino | 1.7 |
| three | Ohino | 3.6 |
| four | Nevada | 2.4 |
| five | Nevada | 2.9 |
df.ix[1] # 切的是行,所以說 ix 默認切的行, 也就是 axis=0
year 2001
state Ohino
pop 1.7
debt NaN
Name: two, dtype: object
非 ix
ix 可以說是 pandas 的標準切法,而沒有 ix 時,情況就略複雜些了,作者說:
索引時,選取的是列切片時,選取的是行
記住一點,如果你想看單列或少數列的索引,那麼直接用 df[‘column’], 其他就
print(type(df['year']))
print(type(df[['year']]))
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
# df['one'] # 會報錯,沒辦法這樣索引,這是行
df[['year', 'state']] # 可運行
| year | state | |
|---|---|---|
| one | 2000 | Ohino |
| two | 2001 | Ohino |
| three | 2002 | Ohino |
| four | 2001 | Nevada |
| five | 2002 | Nevada |
df[0:1] # 切第一行,直接 df[0] 是會報錯的。而 ix 不會。
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohino | 1.5 | NaN |
df['one':'two'] # 所以他也是可以整數切,也能標籤切
| year | state | pop | debt | |
|---|---|---|---|---|
| one | 2000 | Ohino | 1.5 | NaN |
| two | 2001 | Ohino | 1.7 | NaN |
print(df.columns.tolist())
print(df.index.tolist())
['year', 'state', 'pop', 'debt']
['one', 'two', 'three', 'four', 'five']
df.loc[:, 'year':'state']
| year | state | |
|---|---|---|
| one | 2000 | Ohino |
| two | 2001 | Ohino |
| three | 2002 | Ohino |
| four | 2001 | Nevada |
| five | 2002 | Nevada |
df.iloc[:, 1:2]
| state | |
|---|---|
| one | Ohino |
| two | Ohino |
| three | Ohino |
| four | Nevada |
| five | Nevada |
.loc[label] 這是嚴格基於標籤的索引.iloc[inte] 這是嚴格基於整數位置的索引.ix[] 更像是這兩種嚴格方式的智能整合版。
# df.loc[1:2] 用 label 的去切整數,自然會出錯
# df.iloc['two':'three'] 也會出錯
df.loc['two':'three']
| year | state | pop | debt | |
|---|---|---|---|---|
| two | 2001 | Ohino | 1.7 | NaN |
| three | 2002 | Ohino | 3.6 | NaN |
df.iloc[1:2]
| year | state | pop | debt | |
|---|---|---|---|---|
| two | 2001 | Ohino | 1.7 | NaN |
小結:
- 儘量寫兩套切片,除非是索引單列則用 df[column]
- 多用 iloc 和 loc, 除非你很清晰的基於標籤
df2.info() # 說明,ix在這種非整數的整數標籤上,他的切片跟loc一樣,是基於標籤的,而另外兩個剛好相反。